Optimizing the Postgres Cache
Comulate syncs hundreds of millions of insurance policies and processes tens of millions of transactions every month. To do this, we rely heavily on an invisible hero: Postgres.
Until earlier this year, we served all of our customers — over half of the top 100 U.S. brokers — off a single Postgres instance.
This was possible by following a simple vertical scaling strategy: When the database gets slow, make it bigger. As we continued to scale, these upgrades began happening faster and faster, the sheer amount of data and additional load quickly overwhelming each new tier.
This spring, we found ourselves one RDS upgrade away from the highest possible instance size. We needed a new strategy.
Understanding the bottleneck
Before changing architecture, we needed to understand what was actually slowing queries down. At a high level, query slowness often comes from one of two places:
- CPU — when the query is actively doing work; improved by more optimal indexing / scanning fewer rows
- I/O — when the query is blocked on disk reads; improved by serving more data from cache instead of disk
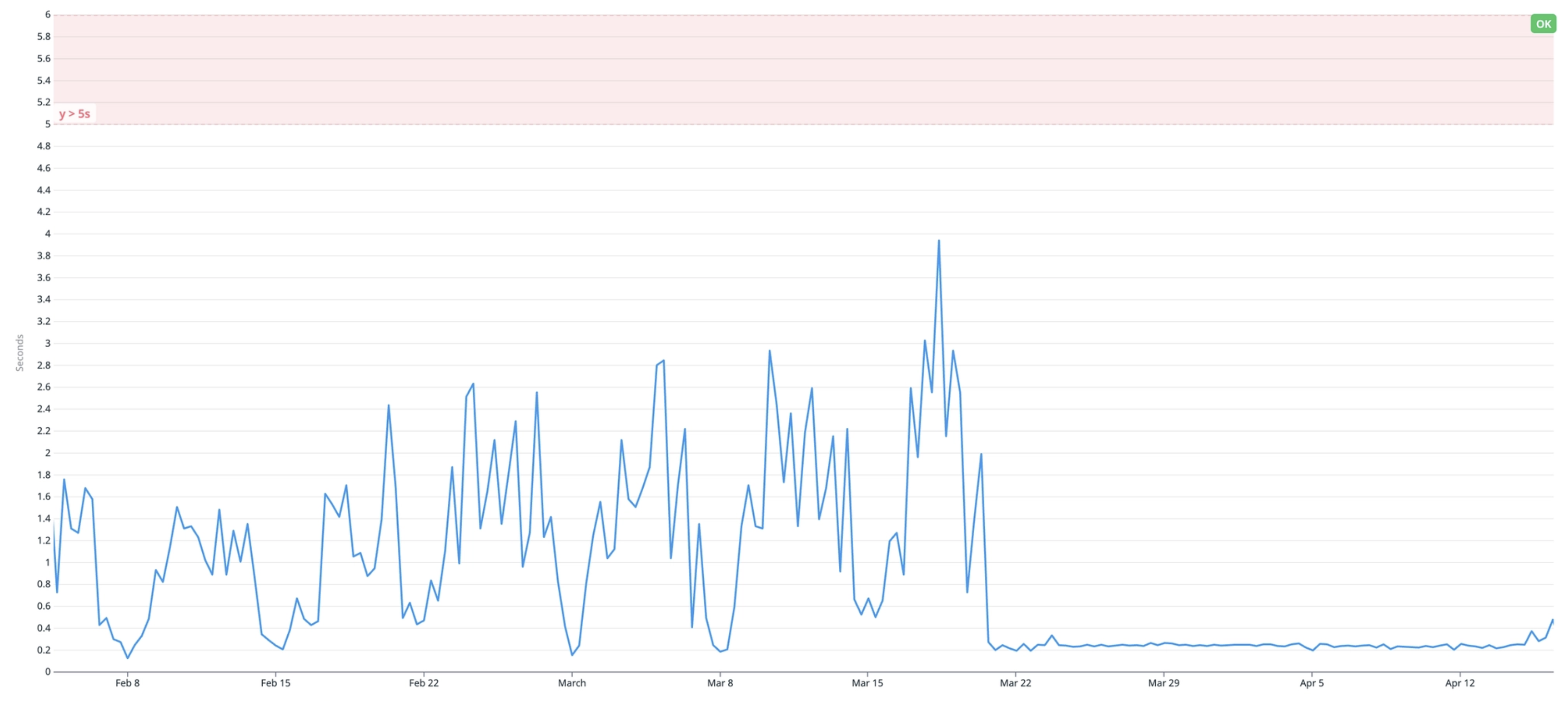
In our case, RDS Performance Insights showed that over half of our database wait time was due to IO:DataFileRead, a clear signal that we were going to disk too often. We also saw that our I/O metrics were consistently maxed out during peak load.


Postgres and its caches
To understand why we were hitting disk so often, it is helpful to know how Postgres manages memory.
Postgres stores data in pages, fixed-size 8 KB blocks. It never fetches a single row from disk — it always accesses the entire page containing the row.
Postgres has two caches for these pages:
- The buffer cache (
shared_buffers), an in-memory pool of pages that read and write operations go through instead of touching disk directly. - The OS page cache, which sits beneath the buffer cache. This is the cache of the host operating system; it is not managed by Postgres and is generally much larger than the buffer cache.

These caches matter a ton for performance: reading a page from cache is ~1000× faster than from disk. Every cache miss forces a synchronous disk read that blocks the query (visible as IO:DataFileRead waits).
Upgrading your instance size results in sizing up your cache, and for our high I/O workloads, we'd see massive performance gains on each upgrade as we could suddenly fit more things in cache.
For the rest of this post, we'll treat these two systems collectively as “the cache”.
Cache effectiveness
When working with a given Postgres instance, there are three key levers you can control for cache effectiveness:
- Pages needed — the number of pages involved every time you read or write to Postgres. Query structure, indexes, and schema decisions can all impact this heavily.
- Cache contents — which pages are in cache at a given time. The data in an effective cache closely matches what the queries need. Importantly, you cannot directly control what Postgres keeps in cache. Instead, it's a function of the workloads you apply to the instance.
- Cache size — the total size of memory caches.
Dedicated workload replicas
One of the first scaling levers we tried was adding read replicas. This is a common first move — the key detail we focused on is that a replica has its own independent caches (both buffer cache and OS page cache).
That makes it possible to “optimize” the cache contents for a specific read-heavy workload rather than having those reads compete with the primary's many competing workloads. For example, if a given workload frequently deals with transactions and those transactions are often evicted from cache on the primary, they'd be able to stay in cache on the dedicated workload replica.
We weighed both splitting reads by customer (i.e. sharding) and by workload. Given our specific workloads, we identified a smaller number of queries with complementary data requirements that alone accounted for ~20% of all I/O wait.
We moved those queries to a dedicated replica and immediately saw a dramatic ~10× improvement in performance on smaller hardware.
When we compare the buffer cache of a dedicated workload replica to the primary, you can see a dramatic difference in the contents.
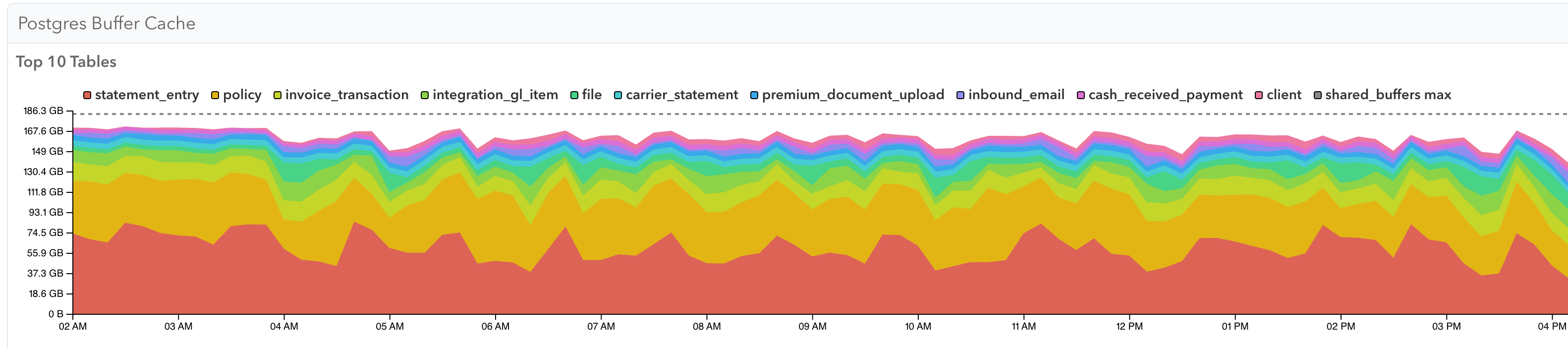
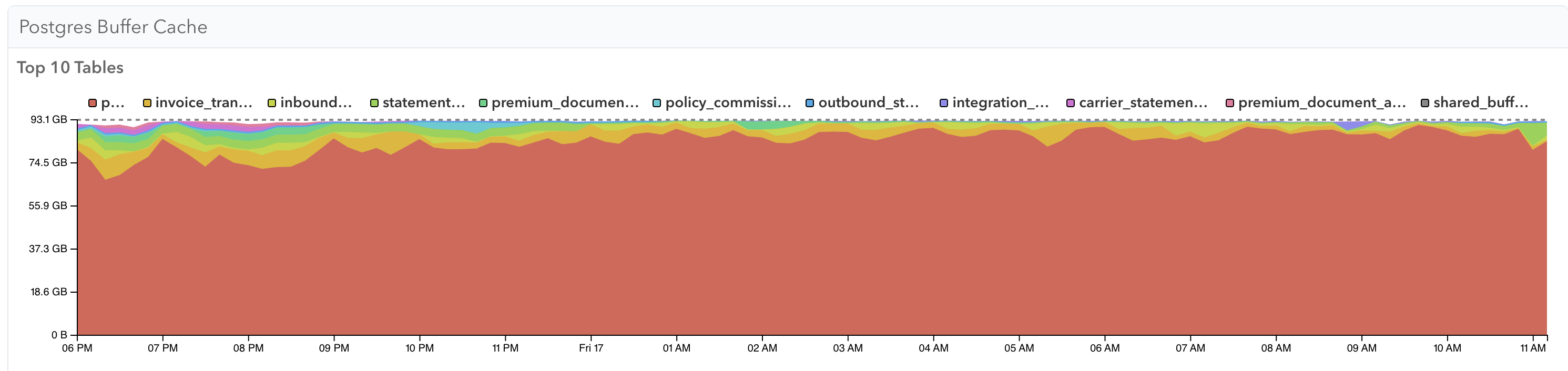
This optimization targeted just cache contents. The pages needed stayed constant and cache size actually went down (for these specific queries on the read replica).
The secondary effect of this change was that our primary's buffer cache also had improved cache contents as it no longer had to “fight” these workloads for cache space, reducing net churn.
Improving the cache
The exercise above gave us confidence that the buffer cache can have a serious impact on performance, which led us to ask ourselves: are there improvements we can make so the primary instance itself has better cache efficiency?
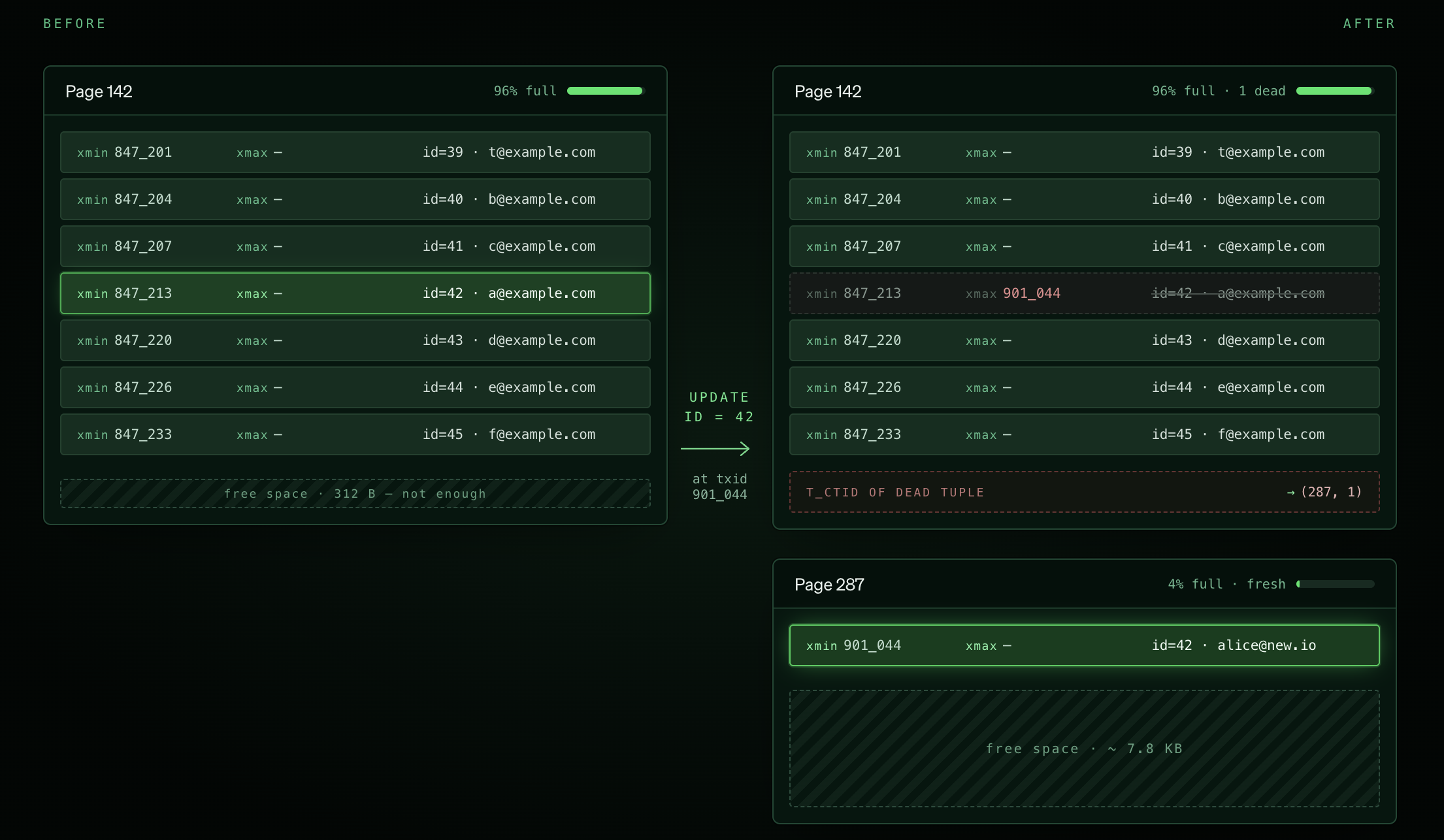
In Postgres, an UPDATE is implemented as MVCC-style versioning, not in-place mutation. The engine writes a new row version into a heap page — pulling that page into the buffer cache if it isn't already there — marks the old tuple as expired, and then, in most cases, has to load and update every affected index page into the buffer cache.
Reducing indexes
Although it is commonly understood that indexing causes more expensive writes (given the index must be adjusted upon write), the second-order impacts of those writes are less commonly discussed.
Specifically, when an index is re-written, it must be loaded into the buffer cache. If you are constantly updating a column with many indexes, this will cause high write amplification, resulting in buffer cache thrash and inadvertently slowing down your entire database.
This was a mindset shift after years of attempting to improve query performance via query tuning and ever-more-specific indexes. We found ourselves with unused indexes and a good reminder that the cost of “throwing an index” on something compounds over time. In some cases, adding an ineffective index can even make reads slower by thrashing the buffer cache without meaningfully reducing work.
Adding an index comes at the cost of making every read that doesn't use that index slower.
Removing unused indexes is a lever to control your cache contents — every index removed is pages that won't pollute your cache.
Increasing HOT updates
Although simply reducing the number of indexes is a great step, ideally there aren't any index inserts for write-heavy operations.
A HOT (Heap-Only Tuple) update lets Postgres write the new row version on the same heap page as the old one — skipping the index updates entirely. This is beneficial because it keeps writes confined to a single buffer-cached page (vs. inserting N additional index pages and evicting existing pages).
Crucially, there are two requirements here:
- The updated column cannot be indexed
- There must be enough free space in the heap page
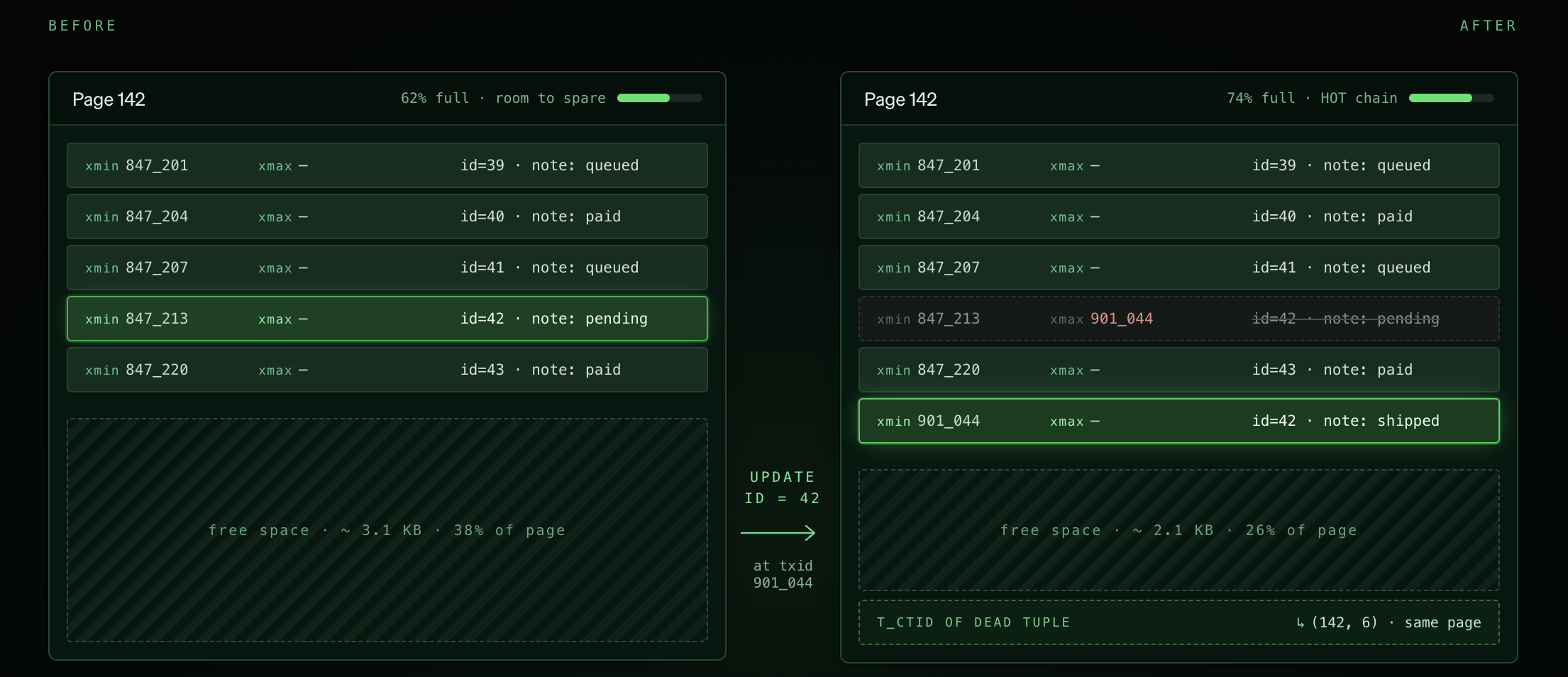
Minimizing indexing on write-heavy columns
To address (1), we discovered that the most commonly updated column on our largest table was both a jsonb column and heavily expression-indexed. The problem: if an UPDATE can't be HOT (because any indexed column changes), Postgres must update all indexes on the table's row — even if most indexed columns' values didn't change. With jsonb expression indexes, small changes inside the jsonb can frequently force non-HOT updates, which then fan out into touching every index.
We moved all legitimately indexed fields in our jsonb column to first-class Postgres columns and dropped all unnecessary indexes on our most frequently updated columns.
Adjusting fill factor
To address (2), the other requirement for HOT updates, we adjusted the fill factor for our most write-heavy tables.
Fill factor is a per-table setting that tells Postgres what percentage of each 8 KB page to fill on INSERT, leaving deliberate free space on each page so that subsequent UPDATEs have room to write the new tuple version on the same heap page.
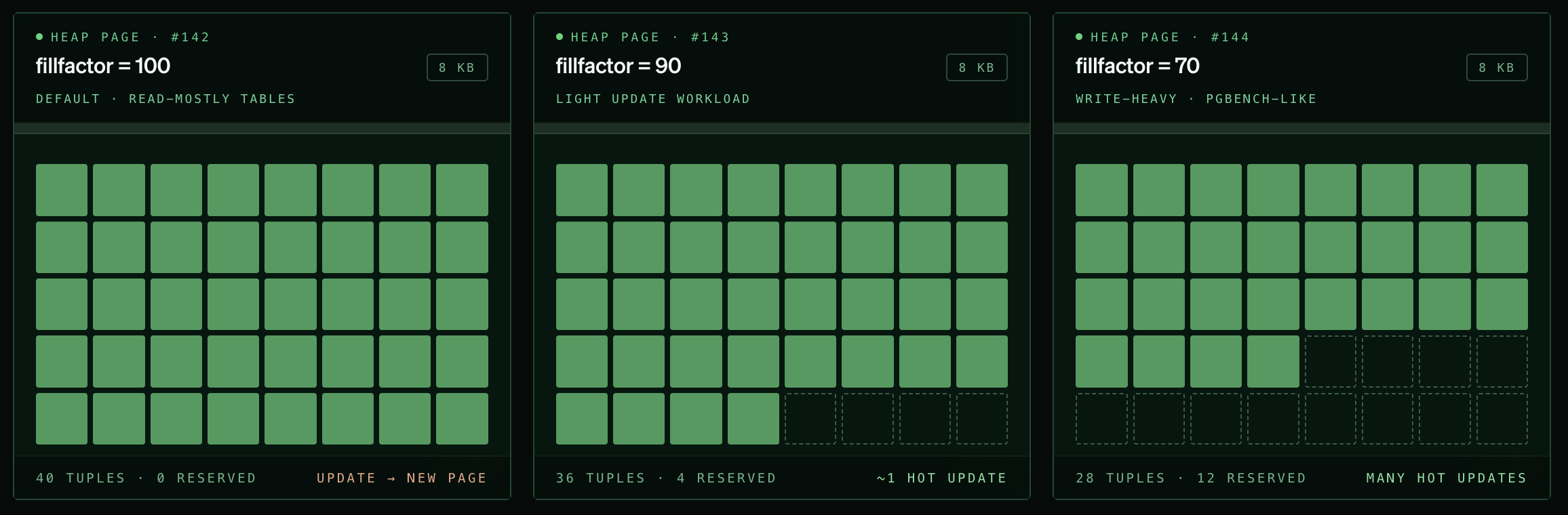
Running pg_repack
Finally, to realize the gains of the changes above (since setting fill factor only affects future page allocations), we ran pg_repack on our table.
pg_repack is a Postgres extension that rebuilds a table (and its indexes) in the background using triggers + a shadow table + a brief lock-swap at the end, achieving the same defragmentation / fill-factor-application as VACUUM FULL but without holding an ACCESS EXCLUSIVE lock for the entire operation (clearly untenable for a production workload).
Impact
At the end of this saga we observed a significant increase in the percentage of HOT updates:
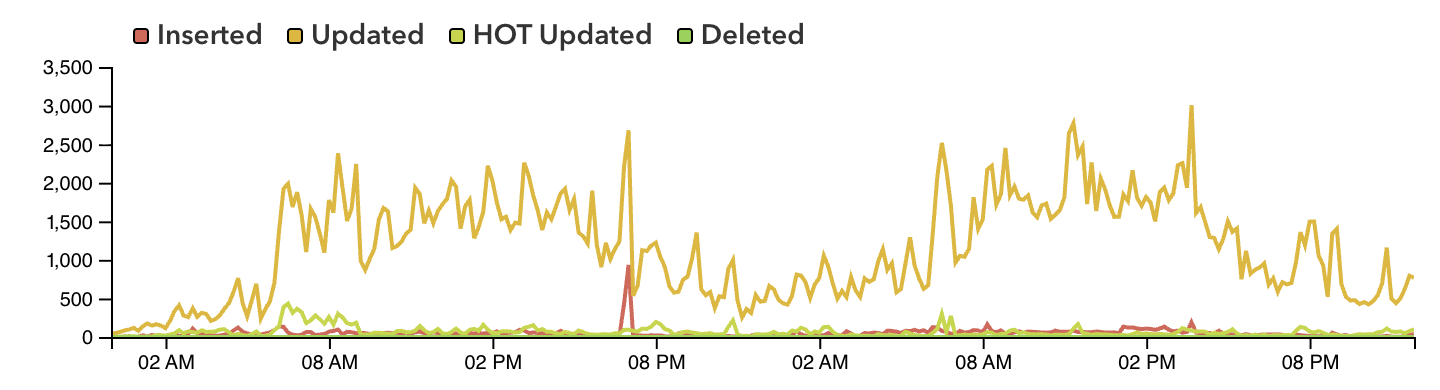
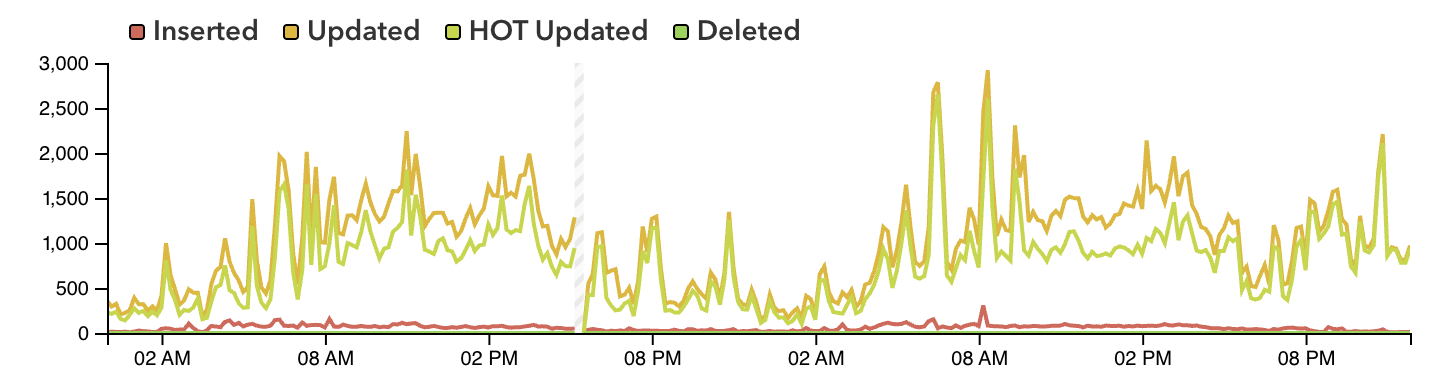
Reconsidering jsonb columns
When we were first building the product, jsonb columns were a useful way to iterate quickly and avoid getting locked into unnecessary design decisions. By storing polymorphic payloads, we could more flexibly support different integrations and specialized use cases.
However, now that the product has matured, we found that some of these jsonb columns were actively degrading database performance. In addition to the indexing issue discussed above, we found our jsonb columns were adding a disproportionate amount of load to the cache.
In Postgres, large column values are bad either way — if they're small enough to stay inline on the 8 KB heap page, they bloat the row so fewer rows fit per page (leading to more pages to read for the same query, more cache pressure).
If they're big enough to spill to TOAST, then a SELECT of that column has to chase the pointer and fault in many TOAST pages, often cold and rarely cached, turning one logical row read into dozens of physical page reads.
We reduced the size of our largest columns in our read-heavy workloads and observed relief in the buffer cache immediately, again after running pg_repack.
Results + looking forward
As hoped, this cut down the overall amount of I/O wait time in our database:
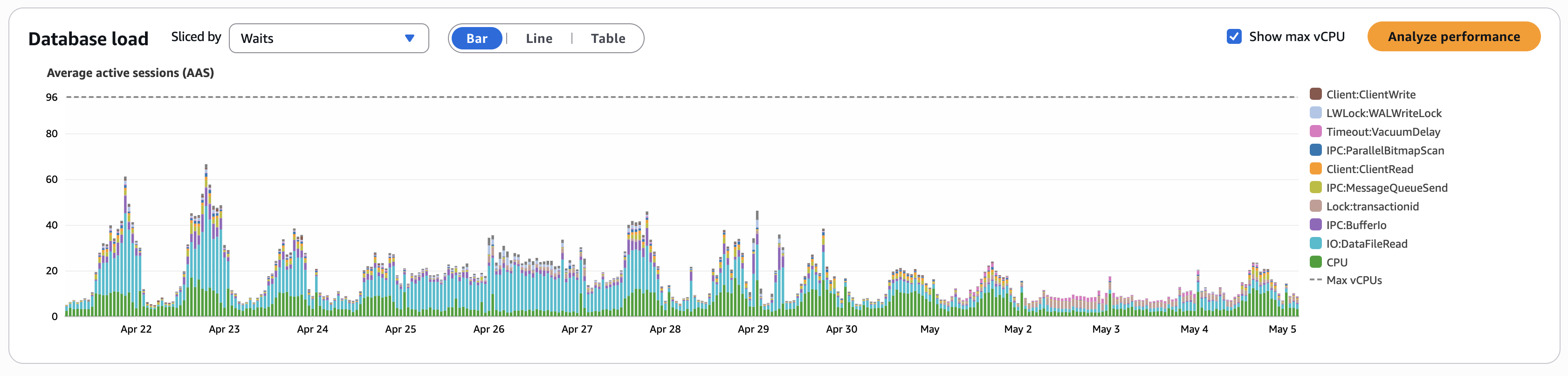
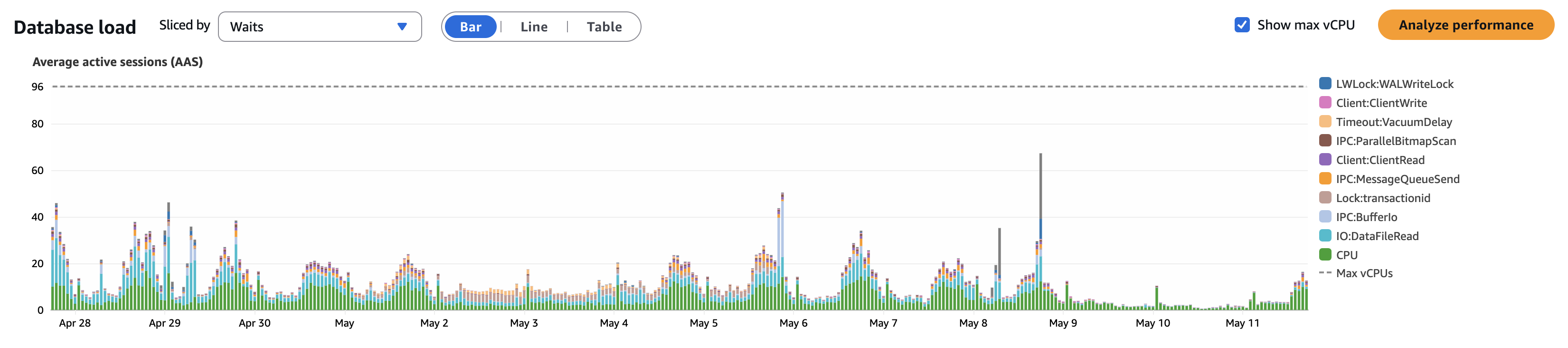
Within pganalyze, we observed improved I/O load metrics:


By isolating like workloads onto replicas and by removing sources of cache churn (unused indexes, non-HOT updates, oversized jsonb payloads), we were able to significantly improve cache contents and reduce pages needed, leading to a more efficient database overall.
The big takeaway for us was that “scaling the database” is not just about bigger instances or more replicas. It's about being deliberate with cache behavior, write amplification, and schema decisions that quietly shape long-term performance. With the primary in a healthier place, we can keep growing with more confidence, and invest our time in horizontal strategies that add capacity rather than just buying back lost efficiency.